In this post, I'll dive into a comparison of two popular machine learning models: Random Forest and Boosted Trees (XGBoost). I will use a dataset from a study on cockle densities in relation to green macroalgal (GMA) biomass in Yaquina Bay, Oregon. By analyzing their performance on this dataset, we'll explore which model is better suited for this type of ecological data.
 Credit: Yakfish Taco
Credit: Yakfish Taco
Introduction to Random Forest and Boosted Trees
Random Forest and Boosted Trees (XGBoost) are two ensemble learning methods widely used in machine learning for classification and regression tasks. Random Forest operates by constructing a multitude of decision trees during training and outputs the class that is the majority vote of the individual trees. This approach helps in reducing overfitting and improving model accuracy by averaging the predictions from multiple trees. On the other hand, Boosted Trees, particularly XGBoost, enhance predictive performance through a technique called boosting. XGBoost builds trees sequentially, where each new tree corrects errors made by the previous ones, and it optimizes model performance by focusing on difficult-to-predict instances. Both methods leverage the strength of ensemble learning but differ in their approach to aggregating predictions, making them suitable for various types of data and problem domains.
 Credit: Janusz Szwabiński
Credit: Janusz Szwabiński
Dataset Overview
The dataset, originally collected during field surveys in June and August 2014, includes various attributes like site, station, survey date, presence of cockles, and environmental factors such as water depth and algal coverage. The target variable, Present, indicates whether cockles were observed in the sampled area.
Preprocessing and Modeling Steps
Let's go through the steps in the Python script used to preprocess the data and train the models.
Loading and formatting the Dataset:
file_path = './cockle-fieldsurveydata-xlsx-1.xls'
df = pd.read_excel(file_path, 'Data')
df.dropna(inplace=True)
% Date parsing
df['Date'] = pd.to_datetime(df['Date'], format='%m/%d/%Y')
for col in ['Easting', 'Shallow_cm', 'Deep_cm', 'Avg_cm']:
df[col] = df[col].astype(str).str.replace(',', '.').astype(float)
for column in df.select_dtypes(include=['object']).columns:
df[column] = LabelEncoder().fit_transform(df[column])
% Feature Selection
X = df.drop(['Uncovered', 'Semi_covered', 'Buried', 'Total','Present','Site','Station','Easting'], axis=1)
y = df['Present']
% Data splitting
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
The features for the model (X) were selected by excluding irrelevant or redundant columns, while the target variable (y) was set to the Present column (which is a binary indicator equivalent to Total>0). Finally, the data was split into training and testing sets, with 80% of the data used for training and 20% reserved for testing.
Justification for Removing Localization Variables
In the context of this analysis, the localization variables such as Site, Station, and Easting were removed during the feature selection process. These variables represent spatial information about the specific locations where samples were collected.
Including these variables could lead to overfitting, where the model learns to associate specific locations with outcomes rather than general patterns that can be applied to new, unseen data. By removing these localization variables, we ensure that the model focuses on ecological and environmental features that are more likely to provide generalizable insights into cockle presence.
Training the Models:
% Random Forest
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
rf_predictions = rf_model.predict(X_test)
% Boosted Trees (XGBoost)
xgb_model = XGBClassifier(use_label_encoder=False, eval_metric='logloss', random_state=42)
xgb_model.fit(X_train, y_train)
xgb_predictions = xgb_model.predict(X_test)
The Random Forest model was trained with 100 trees, and predictions were made on the test set. The XGBoost model was trained with default settings, and predictions were made similarly.
Performance Comparison and Results
After training both the Random Forest and Boosted Trees (XGBoost) models on the dataset, we evaluated their performance using several metrics, including accuracy, precision, recall, F1-score, confusion matrices, and ROC AUC scores.
Accuracy
- Random Forest Accuracy: 0.54
- Boosted Trees (XGBoost) Accuracy: 0.50
Accuracy measures the proportion of correct predictions made by the model. In this case, the Random Forest model slightly outperformed XGBoost, achieving an accuracy of 54% compared to XGBoost’s 50%.
Classification Reports
Random Forest Classification Report:
precision recall f1-score support
0 0.55 0.50 0.52 12
1 0.54 0.58 0.56 12
accuracy 0.54 24
macro avg 0.54 0.54 0.54 24
weighted avg 0.54 0.54 0.54 24
Boosted Trees (XGBoost) Classification Report:
precision recall f1-score support
0 0.50 0.42 0.45 12
1 0.50 0.58 0.54 12
accuracy 0.50 24
macro avg 0.50 0.50 0.50 24
weighted avg 0.50 0.50 0.50 24
From the classification reports, we see that the Random Forest model has a slightly better balance between precision and recall, especially for class 1 (Presence). The F1-scores, which balance precision and recall, show that Random Forest provides a better overall performance with an F1-score of 0.56 for class 1 compared to 0.54 for XGBoost.
Confusion Matrices
Random Forest Confusion Matrix:
[[6 6]
[5 7]]
Boosted Trees (XGBoost) Confusion Matrix:
[[5 7]
[5 7]]
The confusion matrices reveal how well each model distinguishes between the two classes (0 and 1, or Absence and Presence of cockles). Both models show a similar pattern, with Random Forest slightly better at correctly predicting class 1.
ROC AUC Scores
- Random Forest ROC AUC Score: 0.517
- Boosted Trees (XGBoost) ROC AUC Score: 0.594
The ROC AUC score is a measure of the model’s ability to distinguish between classes across all classification thresholds. Here, XGBoost has a higher ROC AUC score (0.594) compared to Random Forest (0.517), indicating that XGBoost has a better overall ability to separate the two classes, despite its lower accuracy.
Feature Importance Analysis
Understanding feature importance is pivotal for interpreting machine learning models, as it reveals which attributes are most influential in predictions. In our analysis of the Random Forest and Boosted Trees (XGBoost) models, we examined how each algorithm evaluates feature importance.
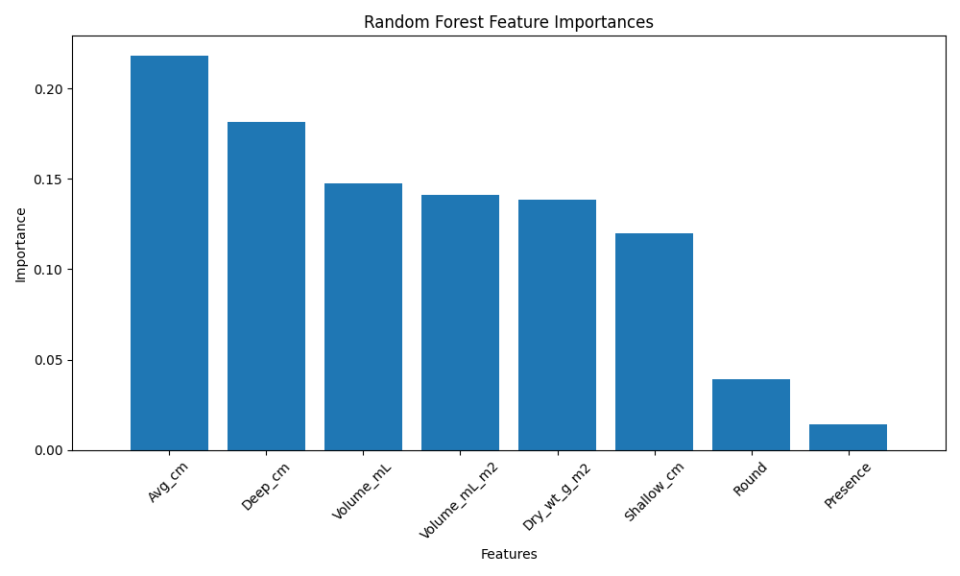
Random Forest determines feature importance by averaging the decrease in impurity across all trees, providing a straightforward measure of how each feature contributes to model accuracy. The resulting feature importance plot highlights key features that significantly influence predictions. The three most important features for the Random Forest model are the mean depth and the deepest depth of the apparent redox potential discontinuity within a subsampled corner of the quadrat, and the volume of wet GMA.
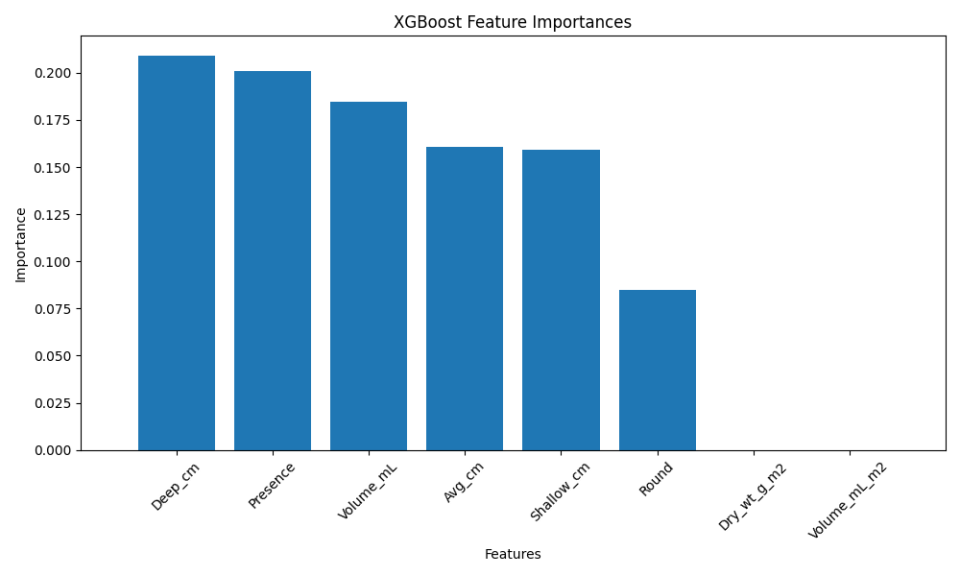
Conversely, XGBoost assesses feature importance based on the gain, which reflects the improvement in model accuracy attributed to each feature. This method can unveil different insights, as XGBoost builds trees sequentially, capturing complex interactions between features. The three most important features for the XGBoost model are the deepest depth of the apparent redox potential discontinuity within a subsampled corner of the quadrat, the GMA presence (binary variable) and the volume of wet GMA.
Conclusion
In summary, while Random Forest achieved slightly higher accuracy and better-balanced classification metrics, XGBoost demonstrated superior performance in terms of ROC AUC score. This suggests that XGBoost might be more robust in identifying the presence of cockles across varying thresholds, making it a valuable model depending on the specific goals of the analysis.
My Python code for this project is available on my GitHub repository. Feel free to check it out here.
Source
The dataset has been found on data.world. It is associated with the following publication: Lewis, N., and T. DeWitt. Effect of Green Macroalgal Blooms on the Behavior, Growth, and Survival of Cockles (Clinocardium nuttallii) in Pacific NW Estuaries. MARINE ECOLOGY PROGRESS SERIES. Inter-Research, Luhe, GERMANY, 582: 105-120, (2017).
 I'm still far from
I'm still far from